

Etude du Code Secret de la Bible - Analyse détaillée
IV- ANALYSE DES TABLEAUX
Des découvertes très imparfaites
Imaginez un chimpanzé à qui l'on a appris à taper sur une machine à écrire. Il frappe au hasard les touches de la machine qui s'impriment sur un papier d'une longueur immense. On obtient à la fin un ouvrage fait de milliards de lettres. Imaginez ensuite un homme perspicace qui cherche à découvrir des mots français parmi ces milliers de lettres consécutives. Avec du temps il risque fort de trouver quelques mots... C'est le principe qui est utilisé pour le Code Secret, mis à part les faits suivants : premièrement, le texte de base est un livre et deuxièmement c'est un ordinateur qui cherche, non un homme.
Si de plus on augmente les chances de faire apparaître des mots cachés en autorisant la recherche par sauts de lettres, avec un travail acharné de recherche combiné à la puissance d'un ordinateur, on aboutit forcément à de beaux résultats.
Si, en une phrase, on voulait résumer la recherche de tableaux de mots avec un ordinateur par la méthode du Code Secret, on pourrait citer une phrase biblique : "Celui qui cherche trouve".
En effet, il faut comprendre qu'il est, mathématiquement, toujours possible de trouver tout ce qu'on désire par le procédé du Code Secret. Il suffit de chercher un bon moment sur un texte assez long et d'avoir un peu d'imagination.
En interrogeant un ordinateur sur la recherche de nombreux mots, celui-ci trouvera toujours un tableau qui rassemble un certain nombre de mots assez jolis. Si l'on s'intéresse plus particulièrement au texte de la Torah qui fait 305 000 lettres, on peut affirmer qu'un mot qui n'est pas trop long pourra être trouvé avec certitude. Les résultats ne sont pas forcément impressionnants mathématiquement, mais on trouvera toujours une association de mots qui traduira ce qu'on désire.
Sous forme de boutade, j'ajouterai dans ce sens que je me suis posé la question de savoir ce qui aurait le plus de succès auprès du public : un livre qui donne la preuve que le Code Secret est faux ou bien un programme qui prédit l'avenir à partir de la méthode du Code Secret.
Il faut bien comprendre que rechercher des mots dans la Torah, par le moyen du Code Secret, n'est pas difficile. Avec un bon ordinateur et un bon programme, on aboutit très vite à des résultats similaires. Nous en avons donné quelques exemples. Pour faire une recherche sur le Code Secret, les opérations à effectuer sont les suivantes :
- L'ordinateur nous demande une liste de mots.
- Il recherche alors dans le texte tous les tableaux qui contiennent ces mots par sauts de lettres.
- Il calcule automatiquement l'espérance des tableaux obtenus.
- Il sélectionne tous les plus beaux tableaux selon les critères que nous désirons, en particulier des tableaux bien compacts.
- Et enfin, il affiche tous les tableaux les plus beaux, en indiquant leur position précise dans le texte.
Il faut aussi avoir à l'esprit que n'importe quel mot qui n'est pas trop long peut être trouvé à proximité de n'importe quel autre avec assurance, pour peu qu'on accepte de le voir apparaître à une certaine distance du mot principal.
La conséquence de cette remarque n'est pas anodine. Cela signifie qu'on trouve pratiquement toujours un tableau qui contienne tous les mots qu'on cherche, seulement le tableau obtenu est parfois assez large. Ou pour le dire autrement : il est possible de faire apparaître pratiquement n'importe quel mot près d'un autre, si on accepte de le rechercher assez loin.
Ainsi lorsqu'on cherche à faire apparaître une idée précise, en révélant des mots cachés à l'intérieur d'un tableau, il suffit d'interroger l'ordinateur et de constater quel tableau est le plus compact parmi tous ceux qui sont proposés. Naturellement, c'est ce tableau là qu'on va exhiber.
Une preuve flagrante que le code secret n'est pas vrai
Voici un argument qui vient donner un coup de grâce à la réalité du Code Secret. Si l'on observe les résultats mathématiques obtenus par le Code Secret, on peut observer qu'il n'y en a pas un qui soit suffisamment impressionnant pour en démontrer l'existence. Ils correspondent tous à ce qu'on pouvait raisonnablement attendre d'une recherche méthodique avec un ordinateur dans n'importe quel texte de taille suffisamment élevée. En effet, pour montrer que le code existe, il suffirait de trouver, par le moyen du saut de lettres, des phrases ou des mots un peu plus longs que ceux qui sont présentés par les défenseurs du Code Secret. Par exemple pour le seul texte de la genese des phrases de 30 lettres, voire même seulement d'une vingtaine de lettres qui aurait un sens clair limpide une grammaire parfaite (autrement dit des phrase que l'on postule a priori), auraient une espérance inférieure à 1 sur cent millions ou 1 sur plusieurs milliards. Ces valeurs commenceraient réellement à être des chiffres impressionnants, même lorsqu'on cherche avec un ordinateur. Mais au lieu de cela on trouve des mots d'une dizaine de lettre qui se croise avec d'autre mots de 7 ou 8 lettres. Etc.
Or jamais, dans aucun tableau du livre, on ne trouve de phrases si longues par le moyen du Code Secret. Il est même assez amusant de voir que dans l'ensemble tout ce qu'on trouve est exactement dans la fourchette de ce qu'on peut attendre.
Il est vrai qu'on trouve bien des phrases composées de plus de 20 lettres, mais c'est curieusement des phrases en clair ; elles sont tout simplement écrites par l'auteur de la Torah...
Une petite parenthèse s'impose ici : il est vrai qu'il arrive aussi que l'on présentedes phrases ayant 60 ou 80 lettres d'affilé. Si 30 lettres suffisent à prouver la validité du code secret, 60 ou 80 lettres semble être une preuve irréfutable non ? En fait, la réponse est non : ces phrases sont très particulières! Elle sont d'une grammaire et d'un sens plus que scabreux. Elles sont fait d'une foule de petits mots et de petites lettres qui s'enchainent (il y a d'ailleurs souvent 1 ou 2 'grands' mots dans la phrases, on comprendra pourquoi quand j'aurais expliqué le principe). Comment de telles longueur de phrases sont-elle possible ? Et bien il faut voir ici une autre technique de recherche de codes secrets. Pour cela il faut être véritable connaisseur de la langue hébraique : l'hébreu étant une langue reposant sur les consonnes, il est très fréquent qu'un enchainement de consonne au hasard puisse forme des mots. Cela provient du fait qu'une grande proportion des différentes combinaisons des lettres (en nombre restreints) aux hasard formes des mots. Evidemment toutes les combinaisons ne forme pas des mots, mais en procédant aux bons regroupements, il n'est pas rare de pouvoir enchainer plusiers dizaines de lettres d'affillé qui fasse des mots. Ce principe de construction du code secret ne repose pas du tout sur la même technique que celle que nous venons d'étudier. Nous venons d'étudier la probabilité de trouver des tableaux de mots désigner à l'avance; alors qu'ici, il s'agit face à un texte de lettre au hasard de fabriquer des phrases. Modéliser ce genre de problème est plus difficile, cela est du à la difficulté de modéliser la notion de "sens" en mathématique. Cette technique de recherche a postériori ne peut-être faite que par des pécialistes en hébreu qui possède une grande agilité littéraire et un grand sens de l'imagination. Et il faut ajouter que ce genre de procéder est vraiment propre à l'hébreux, il ne sera pas reproductible dans la plus part des langues qui utilisent davantage de lettres pour former des mots. Mais suffit-il alors donc d'être spécialiste en hébreux pour former des bon code secret ? En fait, s'il est plus ou moins facile de regrouper des lettres por former beaucoup de mots qui se suivent il est nettement plus difficile de former des phrase qui aient un sens et cela devient carrément impossible de former des phrase qui possède un bonne grammaire. C'est pourquoi là encore le nombre de lettres ne peut pas s'étendre à l'infini, à moins d'être "très souple sur la lecture et le sens", en fait le texte parrait très vite très obscur et insensé si l'on pousse trop loin la méthode. De plus en général pour donner du crédit à ces phrases on va en général chercher à construire ces phrases autour d'un grand mots en donnant du sens aux lettres qui sont avant et après, éventuellement deux mots quand c'est possible. Voilà donc l'origine de la techniques des grandes phrases, on peut aussi se faire vaguement assisté par un ordinateur. Mais dans ce genre de travail l'ordinateur reste toujours limité, car c'est un travail sur le sens, et dans ce domains l'ordinateur ne peut pratiquement rien faire. Au résultats ce sont des phrases de quelques plusieurs dizaines de lettre contenant éventuellement 1 ou deux mots de 8 lettres et puis beaucoup de mot de petit lettre avec toute sorte de curiosité gramaticale et syntaxique nécessaire pour combler les trous et aboutir à un sens à la limite ru recevable. Car des phrases de 60 à 80 lettres qui serait d'une limpidité sémantique et d'un grammaire nette serait des improbabilités extrêmes, pour la simple et bonne raison que les règles de composition des phrases sont rigides et limitent les combinaisons valides de façon drastique. Ces grandes phrases qu'il arrive donc de voir ici ou là publié, ne sont pas (en tout cas celles qui sont parvenu à ma connaissances) des phrases claires (et il ne faut pas être expert en ébreu pour s'en rendre compte), mais au contraire d'une ambiguité, d'un sens obscur et d'une difficulté extrême à être claire. Elle ressemble "étrangement" aux phrases que l'on pourrait construire en cherchant des mots bout à bout. Si je n'ai pas abordé l'étude mathématique de cette technique dans ce livre, il y a plusieurs raisons : la première est que cette technique est assez pratiqué car il faut des gens pratiquent l'hébreu plus que couramment et qui accepte des sens pour le moins curieux (Mais le procédé semble tout de même prendre un peu plus d'envergure ces dernier temps). La troisième raison est qu'il mathématiquement difficile de modéliser la technique à cause de l'aspect sémentique. La troisième raison est que je me suis essentiellement centré sur le travail de Drosnin qui est le plus répandu.
Il existe aujourd'hui en effet de très nombreuses technique qui se sont développé autour du code secret Et Chacune d'elle demanderait une étude mathématiques particulière, mais de tous les travaux qui me sont passé sous les yeux, aucuns ne semble sortir du malheureux principe suivant : "on constate des résultats très beau, c'est donc qu'il y a une intervention divine". Personne ne s'intéresse à mesurer si les résultats qu'il obtient sont "normal ou non", alors que c'est la la seule question qui soit intéressante pour valider les travaux. Ce n'est pas d'obtenir des résultat psychologiquement joli qui est intéressant, cela est facile à produire avec des ordinateurs. Mais c'est d'obtenir des résultats anormalement joli. Si je me suis concentré sur les travaux de Drosnin, c'est parce que son livre a fait beaucoup de bruit. Mais je ne saurais trop insister pour faire savoir que les travaux ayant trait au code secret se multiplie et surtout se diversifient dans les procédés, dans les approches. Mais dans toutes les techniques que j'ai observé, aucun auteur ne cherche à évaluer si les travaux qu'il fait présente sont des résultats normals ou non. Je suis même assez choqué de voir que de prétendus "hommes de science" abondent aussi dans ce sens : se laisser impréssionné sans vérifier, sans quantifier, sans mesurer les résultats obtenus.
Si Dieu avait réellement caché des prophéties dans le texte par le moyen du Code Secret, n'aurait-il pas eu la sagesse, la capacité de cacher des phrases plus longues et très claire qui montreraient réellement que c'est lui qui a écrit ces choses ? Dieu n'est-il pas assez puissant pour cacher des phrases de 30 lettres d'une clarté déroutante ?
Or si des grandes phrases cachées de 20, 30 ou 40 lettres étaient courantes dans le texte biblique, avec tous les travaux qui ont été réalisé, quelques unes de ces phrases auraient déjà été trouvées. Il serait en effet bien facile de les faire apparaître. Avec un ordinateur, on peut trouver très facilement la position dans le texte à laquelle apparaît n'importe quel mot choisi dans le texte. Il suffit alors de regarder si les mots qu'on trouve sont inclus à l'intérieur d'une phrase claire. Pour constater cela, il suffit de regarder les lettres qui précèdent le mot et celles qui le succèdent. Si le mot se trouve inscrit à l'intérieur d'une phrase, cela est très vite repéré ; il suffit de connaître un peu l'hébreu. On s'aperçoit ainsi que la technique pour trouver des grandes phrases serait très simple à réalisé, encore faut-il que de telles phrases existent. Le fait de trouver ces grandes phrases serait aussi très convaincants. Or voilà de nombreuses années que beaucoup d'hommes s'acharnent à ces recherches sur le Code Secret, et encore personne n'a jamais fait apparaître une seule grande phrase qui soit une phrases claire ...
Si Dieu a créé un monde si complexe, s'il a créé la vie, n'aurait-il pas pu donner dans le Code Secret des exemples réellement convaincants ? Il suffit de regarder la complexité d'une cellule vivante. Le code de l'ADN, lui, est un code véritablement extraordinaire : en une seule molécule qui ne pèse même pas quelques millièmes de grammes, se trouvent contenus non seulement tout le plan d'un être humain, mais aussi des outils qui permettent de le construire. A la différence du Code Secret, l'ADN peut être vu comme un code réellement divin. A la différence de l'ADN, c'est peu de choses de trouver quelques mots qui se croisent dans un tableau produisant tout juste un résultat à la hauteur de nos piètres machines informatiques. Il est peut-être un peu osé de la part d'un homme d'y voir la sagesse de Dieu.
Des constatations gênantes
Il me semble que nous disposons d'assez d'arguments pour infirmer la validité du Code Secret ; mais il y a encore tant d'autres constatations qui viennent s'ajouter qu'il faut tout de même en parler. Chacune de ces constatations est de nature suffisante à mettre en doute le Code Secret de la Bible.
Voici en particulier une remarque qui porte considérablement atteinte au Code Secret. Pourquoi les tableaux produits par la méthode du Code Secret sont-ils faits de mots en vrac sans coordination ? Pourquoi le sens et la structure des prophéties doivent-ils être précisés par des éléments qui ne sont pas contenus dans la découverte ? Pourquoi ne trouve-t-on jamais de phrases écrites complètement dans un bon hébreu avec tous les mots de coordination d'une grammaire correcte ?
N'est-ce pas tout simplement parce qu'il est très difficile de trouver des phrases bien construites ? La plupart des tableaux trouvés rassemblent des mots épars dont il faut trouver l'interprétation, comme si le Code Secret était élaboré dans un langage sous-évolué. Pour prendre un exemple, les mots suivants 'Effondrement économique', 'Action', '1929' et 'Dépressions' ressemblent-ils vraiment à une prophétie divine annoncée par un auteur inspiré lors de la rédaction du texte pour prédire qu'en 1929 une grande crise économique toucherait le monde occidental par le biais de la chute des actions à la bourse ? Une phrase claire serait quand même la bienvenue pour annoncer une prophétie.
Ce langage sous-évolué est-il celui de Dieu ? La Bible contient des vraies prophéties écrites en clair par des prophètes voici plus de 2000 ans. Ces prophéties sont écrites en bon hébreu. Il est vrai que de nombreuses phrases parmi ces prophéties ont parfois un sens assez caché, mais elles sont toujours écrites dans un langage correct.
Dieu aurait-il voulu faire des économies de place, en cachant les prophéties par le Code Secret, en livrant uniquement des mots à la place de phrases ? Ou bien est-ce plutôt que les mots sont faciles à trouver alors qu'une longue phrase en continu serait pratiquement impossible ?
Ces mots hachés dont il faut soi-même faire l'interprétation ne révèlent-ils pas la pauvreté des tableaux ? Si Dieu avait voulu le faire, il aurait sans doute mieux fait. Ne voit-on pas clairement l'imperfection humaine dans ces mots dispérsée, cette grammaire très disloquée... ?
Les seules phrases bien construites sont celles qu'on trouve en clair dans le texte. Trouver des phrases bien tournées par le procédé du saut de lettres serait difficile, car les vraies phrases ont souvent beaucoup de lettres. Le calcul montre que trouver des phrases de plus de 12, 13 voire 14 lettres est une tâche qui commence à devenir difficile, alors ne parlons pas de 15, 20 ou 30 lettres... Si de telles phrases apparaissaient régulièrement (des phrases bien faites de 30 lettres, 40 lettres) on commencerait à se poser sérieusement des questions, car le calcul montre que cela serait vraiment prodigieux. Mais malheureusement ce n'est pas le cas. L'essentiel des mots obtenus par le procédé du code possède moins de 8 lettres ; très peu de mots en possèdent plus. Dans les résultats proposés, la phrase la plus longue comporte 11 lettres. Il est, une fois de plus, surprenant de constater que les limites des mots qui ont été trouvées sont justement celles qu'on pouvait prévoir par le calcul.
Ces découvertes sont-elles vraiment extraordinaires ?
Dans le livre de Drosnin, bien des prophéties annoncées ne se sont pas accomplies. Cela pose un réel problème, car si tout ce qu'on trouve par le moyen du Code Secret peut être remis en cause, quel intérêt possède le Code Secret ?
Le fait de trouver des prophéties qui ne se sont pas accomplies nous conduit à la question suivante : lorsqu'on recherche et qu'on fait le compte des idées intéressantes qu'on a découvertes, trouve-t-on plus de prophéties qui s'accompliront ou plus de prophéties qui ne s'accompliront pas ?
L'auteur propose une explication : il dit tout simplement qu'il existe plusieurs futurs possibles et que le texte biblique contient toutes les prophéties de tous les avenirs possibles. Mais une telle affirmation ne résout aucunement le problème, et même bien au contraire il conduit à des incongruités encore plus grandes. Voyons où cela nous mène:
Si l'on considère que les prophéties de la Bible prévoient toutes les éventualités, on peut constater que les prophéties qui ne s'accompliront pas doivent être bien plus nombreuses que les autres. En effet, pourquoi est-ce que plusieurs avenirs sont possibles ? C'est tout simplement parce que nous avons le pouvoir de choisir, nous pouvons influencer l'avenir. Si par exemple un homme choisi de se présenter ou non à des élections, il se peut que l'avenir de toute l'humanité soit complètement différent. Ainsi si l'on veut estimer tous les avenirs envisageables, le nombre se démultiplie par autant de choix qu'il est donné à chaque homme de faire à chaque instant. De cette façon, les différents avenirs possibles se multiplient à une vitesse effroyable. Etant donné que chaque seconde des millions de choix ont lieu sur la terre par tous les hommes, comment compter tous les avenirs possibles ? En plus, nous n'avons comptabilisé que les choix humains ; il y aurait beaucoup d'autres choses à prendre en compte. Il ne faudrait pas plus de quelques minutes pour que le nombre de tous les avenirs possibles s'élèvent à des milliards de milliards de milliards de milliards etc... Pourtant un seul avenir aura lieu. Si jamais les prophéties du Code Secret prévoient toutes les éventualités, imaginons ce qu'elles doivent contenir... Parmi toutes les prophéties qu'on peut trouver, il serait difficile de savoir lesquelles sont bonnes.
De plus une petite réflexion mathématique est la bienvenue dans cet ordre d'idée : pour que des milliards et des milliards d'avenirs puissent apparaître dans la Bible, il faudrait encore qu'ils aient la place d'y figurer... or cela est impossible. Drosnin cite Rips (p.48,49) en disant qu'il n'y a pas de limite à ce qui est révélé dans la Torah. Il dit que TOUT y est consigné. Or, contrairement à ce qu'affirme Drosnin, un peu plus de 300 000 lettres ne permettent de consigner que très peu de chose. Tentons de comprendre cela : servons-nous des ordinateurs pour en illustrer l'explication. Ces machines électroniques, qui nous rendent bien des services, utilisent un langage très simple appelé le langage binaire. Celui-ci n'est fait que de deux signes 0 et 1. C'est par une quantité de calculs extrêmement importante et rapide à partir des deux symboles uniques de son alphabet que l'ordinateur parvient à faire tous ce qu'il réalise sous nos yeux.
Imaginons maintenant qu'un homme se demande combien d'argent il dispose sur son compte en banque. Devant lui se trouve un livre écrit dans l'alphabet informatique ; ce livre est fermé. On lui a affirmé qu'en ouvrant ce livre, il y trouverait la réponse à sa question, il suffira de savoir interpréter les symboles qu'il y trouvera par une méthode précise. Interrogeons-nous maintenant sur les informations que peut donner ce livre. Si celui-ci ne contient qu'une seule lettre de l'alphabet informatique, combien d'informations peuvent être donner par ce livre ? Il n'est pas possible de donner des milliards d'informations avec une seule lettre, il uniquement possible d'en donner 2 différentes : soit le symbole présent est le 0, soit c'est le 1. Dans le cas où l'homme avait posé une question de la forme: "Ai-je bien 62 314,40 F en banque", le livre aurai pu lui dire Oui ou Non, car un symbole est suffisant pour répondre à une question par Oui ou Non, en interprétant le 1 par Oui et le 0 par Non. Mais un symbole informatique ne peut pas faire plus que donner deux alternatives. Si l'homme attendait le nombre précis correspondant à une certaine somme d'argent, le livre ne pourrait pas lui indiquer avec une seule lettre. Un livre ne contenant qu'un seul symbole peut laisser entrevoir uniquement deux alternatives et pas davantage. Imaginons maintenant que le livre contienne 2 symboles, combien d'informations différentes peut-il contenir ? La réponse est 4, soit on y trouve les symboles 01, soit 00, soit 11, soit 10. Ainsi le livre peut répondre à une question qui possède au maximum 4 alternatives, ou encore il peur répondre à deux questions par Oui et par Non. Avec trois de ces symboles informatiques, il peut informer de 8 alternatives possibles, et ainsi de suite il est très facile de calculer à combien d'alternatives différentes peut répondre un livre contenant un nombre de symboles connu ; chaque nouveau symbole multiplie par deux les alternatives possibles. Le calcul semble facile car nous avons affaire aux symboles simples 0 et 1, mais il en est exactement de même avec l'alphabet hébreu. Celui-ci est composé de 22 lettres, une lettre fournit donc 22 alternatives possibles, et 305 000 lettres fournissent 22305 000 alternatives possibles. Par un calcul simple (22 305 000 = 2 1 360 127) on trouve que la Torah ne peut absolument pas répondre à plus de 1 360 127 questions par Oui ou par Non (Exprimé sous forme d'alternatives possibles, on obtient un nombre qui s'écrirait avec plus de 400 000 chiffres, ce nombre correspond aux combinaisons de réponses possibles obtenu par 1 360 127 questions) Aussi surprenant que cela paraisse, ces 1 360 127 réponses sont le maximum que l'on puisse tirer de la Torah. Alors en posant les questions suivantes: "Est-ce que je vais cligner de l'oeil lors de ma première inspiration de l'année qui arrive ?", "Est-ce que je vais cligner de l'oeil lors de la deuxième inspiration de l'année qui arrive ?", "Est-ce que je vais cligner de l'oeil lors de la troisième inspiration de l'année qui arrive ?", et ainsi de suite pour toute l'année. Et bien cela fait déjà trop de questions pour que la Torah puisse y répondre ? On voit très vite les limites, 305 000 lettres ne nous répondraient que pour environ 80 jours (ce qui correspond environ à 1 360 127 respirations). On comprend donc qu'il est encore moins possible d'y trouver tous les secrets des sciences naturelles, de la physique, de l'histoire et de je ne sais quelle autre informations réunies. Un nombre de lettres donné n'apporte qu'un nombre de réponses limité ; c'est un fait mathématique incontournable, à moins de tricher, bien évidement... Drosnin expose (toujours p.48) un explication apportée soi-disant par Rips affirmant que le nombre d'informations apportées par ces 305 000 lettres est incalculable, infini. Comme nous venons de le voir, cette affirmation est erronée. Il revient à peu près au même de dire qu'à l'intérieur de l'alphabet français :
a b c d e f g h i j k l m n o p q r s t u v w x y z
il se trouve caché tous les secrets de l'univers ! Et pourtant c'est presque vrai : il suffit de lire les lettres les unes après les autres et de former à notre convenance des mots et des phrases et autant d'explications que nous désirons en former. Personne ne contredira que l'on peut dire tant de choses avec l'alphabet français. Seulement dans ce petit jeu, ce n'est pas les lettres qui révèlent les secrets, c'est celui qui fixe l'ordre dans lequel sont lues ces lettres. Et bien il en est de même pour la Torah, le nombre d'informations peut être effectivement illimité si l'on s'autorise à prendre les lettres dans l'ordre que l'on veut... Il est bien plus enrichissant de lire ce qui se trouve réellement écrit dans le livre par l'auteur, plutôt que de se substituer à l'auteur et de se méprendre sur soi-même.
Nous avons là une réponse de plus : la prophétie n'est pas illimitée, elle ne peut donc tout entrevoir. Il faut alors qu'elle ne se trompe pas, car elle ne peut apporter que peu d'information. Or apparemment, sur le peut de réponse qu'elle peut fournir, elle peut se tromper...
La conclusion de cette réflexion est que si l'on ne peut pas faire confiance à des prophéties, si tout ce qu'on trouve peut être remis en cause, il y a vraiment très peu d'intérêt au Code Secret. D'ailleurs la Torah dit elle-même qu'on peut reconnaître un vrai prophète à l'accomplissement de ses prophéties. Dans le cas où les prophéties ne se réaliseraient pas, la Bible dit que le prophète doit être considéré comme un usurpateur et qu'il devrait être puni très sévèrement... Si la Torah elle-même n'admet pas que des prophéties se trompent, est-il raisonnable de penser qu'elles ont le droit de faire fausse route dans le Code Secret ? Dieu change-t-il de politique ?
La Torah est faite d'environ 305 000 lettres. Cela parait très grand ; et pourtant, on pourrait faire apparaître toute la Torah sur une seule grande page dans un tableau de 552 caractères sur 553. Si les lettres étaient inscrites dans des cases de 2 millimètres sur 2 - ce serait des petits caractères, mais tout de même assez lisibles - alors toute la Torah rentrerait dans une page de 1m10 par 1m10. En imprimant des caractères visibles à la loupe dans des cases de 0.45 mm sur 0.45, alors toute la Torah serait inscrite sur une feuille de format A4 (21cm sur 29.7cm). Cela peut nous donner une idée de la taille de la Torah. Elle n'est pas si grande que cela, même si elle occupe 335 pages dans un livre petit format en alphabet hébreu assez large.
Que peut-on tirer de cette constatation ? Tout simplement que, sur une seule page, on peut faire apparaître la quantité effarante de 23 000 000 000 de positions possibles pouvant être occupées par n'importe quel groupe de 3 lettres. Ce nombre impressionnant de positions peut être visible d'un seul coup d'oeil. Il faut se rappeler que plus de 60% des groupes de 3 lettres faits au hasard ont une signification. En procédant au calcul de 60 % des 23 000 000 000 de positions, on peut imaginer comme il est facile de faire des associations d'idées avec 14 000 000 000 de mots. Ainsi, en pensant à tous les mots qui se croisent dans toutes les directions, on obtient des milliards de milliards... d'idées possibles faites uniquement à partir de mots de 3 lettres. Ces résultats sont loin d'être des prophéties inscrites par une volonté divine, mais simplement une constatation établie sur des combinaisons hasardeuses.
Toute cette foule d'idées qu'on peut réunir sur une seule page peut encore faire réfléchir. Si dans chacun des tableaux du livre "La Bible : le Code Secret", on faisait apparaître tous les mots possibles qui s'y trouvent, il y aurait des milliers d'idées possibles. Beaucoup d'entre elles seraient même très contradictoires. Finalement on peut se demander pourquoi l'auteur en a fait apparaître certaines plutôt que d'autres ? N'a-t-il pas fait apparaître uniquement les mots qui l'intéressent ? Les autres mots qui pourraient apparaître seraient bien souvent gênants. Cette simple remarque est à nouveau suffisante pour s'interroger sur les tableaux qui nous sont présentés. Finalement, avec un peu d'imagination et de débrouillardise, ne peut-on pas faire dire n'importe quoi à n'importe quel tableau ?
Comment produire de très bons résultats ?
Nous avons vu plusieurs remarques bien gênantes pour le Code Secret. Nous allons maintenant montrer comment construire des tableaux qui offrent de bons résultats mathématiques.
Si l'on désire trouver des mots assez rares dans un texte hasardeux, si l'on veut produire des tableaux qui soient assez impressionnants, il existe deux techniques de recherche :
- La première technique consiste à formuler une idée avec plusieurs mots différents. Plus les mots choisis sont nombreux et "faciles" plus les chances de trouver ces mots sont grandes. Un mot "facile" est un mot qui a peu de lettres et dont les lettres sont courantes. Ainsi, plus un mot est "facile", plus son apparition sera fréquente.
Imaginons qu'on cherche à produire un tableau contenant quatre idées. Supposons que la première idée puisse s'exprimer par 5 mots différents, la deuxième par 7 mots, la troisième par 6 mots et la 4ème par 5 mots. Si l'on choisit un mot précis pour chacune de ces idées, l'espérance de trouver un tableau contenant ces quatre mots est en général assez faible. Par contre, si l'on s'autorise à trouver indifféremment n'importe lequel des mots exprimant chacune des idées recherchées, l'espérance de trouver un tableau se multiplie par 1050 (= 5 x 6 x 7 x 5). En effet, le nombre de combinaisons différentes par lequel on peut exprimer une idée se calcule, non pas en ajoutant, mais en multipliant les différentes formulations possibles. Dans l'exemple que nous venons de citer, avec 23 mots (=5+6+7+5) au lieu de 4 (en exprimant chaque idée d'une seule manière), soit seulement 5.75 fois plus, on multiplie les chances par 1050.
En utilisant ce principe, si l'on veut produire des tableaux ayant une espérance très faible, il est intéressant de chercher tout une liste de mots qui exprime juste quelques idées. Ainsi, les espérances se multiplieront par les différentes formulations possibles. Avec des tableaux où se croisent 6 ou 7 mots, on arrive très facilement à des espérances de 1 sur 10 000 ou de 1 sur 100 000, et même bien moins encore.
Par exemple avec 11 idées exprimés chacun de 11 façons différentes, soit 121 mots, on peut constituer plus de 285 000 000 000 groupes de 11 mots qui présentent la même idée. Chacun de ces groupes pouvant apparaître dans un tableau, l'espérance de voir apparaître notre idée se multiplie par 285 000 000 000. De cette façon, on peut vite arriver à des espérances très petites. Il ne faut donc pas être impressionné même par de très grands (ou très petit) chiffres.
- Le seconde technique est la méthode opposée : au lieu de chercher plusieurs mots qui se croisent, on cherche une seule longue phrase.
Il faut de préférence commencer par chercher des mots ayant une assez grande espérance : une espérance de plusieurs centaines ou plusieurs milliers au minimum. Pour chacun des mots que l'ordinateur aura trouvé, il faut voir si les lettres qui sont avant ou celles qui sont après (selon les mêmes sauts de lettres) peuvent s'ajouter à côté du mot concerné pour former un sens. En résumé, il faut regarder si le mot s'inscrit dans une phrase.
Nous avons vu qu'aucun mot ne s'inscrit dans une grande phrase, par contre il arrive très souvent que des mots s'inscrivent dans une petite phrase. Par quel phénomène cela se produit-il ? Pourquoi peut-on espérer trouver des mots s'inscrivant dans une petite phrase ? Et bien, il faut se rappeler que 60 % des mots de 3 lettres ont un sens en hébreu. Ainsi lorsqu'on trouve un mot par la méthode du Code Secret, il arrivera dans 60% des cas que les 3 lettres placées avant forment un sens ; de même pour les 3 lettres d'après. Par un petit calcul , on obtient donc que dans 84% des cas (0.60cas où un mot avant existe + [ 0.40 cas où un mot avant n'existe pas x 0.60 cas où un mot après existe] = 0.84) le mot trouvé peut être rallongé par un autre mot d'au moins 3 lettres. Il est clair que largement moins de ces 84% de cas produiront une phrase sensée. Il est tout de même raisonnable de penser que les mots formeront un sens intéressant dans un certain nombre de cas ; et certainement même assez souvent. C'est d'ailleurs la raison pour laquelle cette technique est efficace. Il faut certainement un temps de recherche important avant de trouver des mots se regroupant de manière vraiment intéressante ; mais lorsqu'on a trouvé une suite de mots par cette méthode, on constatera que l'espérance est souvent plutôt faible.
En résumé : lorsqu'on cherche à "rallonger" les mots en regardant les lettres autour, on trouve régulièrement des combinaisons intéressantes, en particulier des petits mots de deux, trois voire quatre lettres.
Cette technique pose un gros problème mathématique. Il est extrêmement difficile de mesurer la part des mots qui forment un sens en les associant, c'est-à-dire qu'il est pratiquement impossible de prévoir la proportion des découvertes favorables par cette technique.
On peut s'assurer que l'espérance n'est pas très faible, mais il sera impossible de l'estimer ou même d'en donner un ordre de grandeur autrement que par une étude statistique qui devrait être gigantesque. Cette difficulté provient du fait que nous sommes incapables de mesurer la quantité d'ordre qu'il existe dans le hasard des mots. Certains hasards contiennent beaucoup d'ordre. C'est le cas des naissances : c'est un processus hasardeux qui détermine comment sera l'enfant ; et la plupart des enfants, heureusement, arrivent en bonne santé. Dans un certain sens, on peut dire que ce hasard contient beaucoup d'ordre.
A l'instar de cet exemple, il est clair que le processus d'extension des mots que nous avons décrit contient aussi une certaine dose d'ordre ; c'est-à-dire une certaine quantité de réussites. Il arrivera moins souvent de trouver un mot ayant un sens que de constater une naissance en bonne santé ; mais on constatera tout de même une certaine quantité de découvertes favorables. Ce phénomène a lieu dans la langue hébraïque plus que dans les autres langues. Cela provient entre autre du fait que l'hébreu contient énormément de mots de 3 lettres.
Il faut pourtant faire une remarque importante concernant cette méthode. Les résultats qu'elle produit sont complètement hasardeux ; il ne faut pas s'attendre, par cette méthode, à trouver une phrase précise qu'on a choisi. Par contre, on pourra trouver des phrases, même assez longues, qui ont un sens ; un sens que nous n'attendons pas avant de l'avoir découvert, un sens hasardeux.
Il faut tout de même penser qu'en utilisant cette technique nous choisissons le premier mot, voire les deux premiers, avant de rechercher des lettres autour. Nous avons donc un certain pouvoir sur le sens de la phrase : nous en avons sur le mot proposé à l'ordinateur, mais nous n'en avons pas sur le reste de la phrase, sur les lettres qui entourent ce mot. Cette remarque est importante, car lorsqu'on trouvera des phrases très impressionnantes mathématiquement, mais un peu bizarre du point de vue du sens, il faudra probablement penser que c'est cette technique qui a été utilisée.
Lorsque la découverte est faite, il est toujours possible de tricher, selon le principe de l'antériorité que nous avons déjà expliqué. Mais avec un peu de perspicacité, il est souvent possible de distinguer un contexte fait de toute pièce d'un contexte indépendant d'une volonté.
La conclusion que nous pouvons apporter sur ce second procédé est qu'il peut aussi conduire à de bons résultats. Mais étant donné qu'il est impossible de mesurer des résultats issus de cette technique, nous serons obligés de conserver le modèle général même pour les tableaux ayant recours à ce procédé. Ainsi notre modèle ne prend pas en compte l'existence d'un peu d'ordre dans le désordre des lettres. C'est la raison pour laquelle, dans ce genre de situations, on constatera des espérances mathématiques plutôt faibles, bien que les résultats soient finalement assez naturels.
Nous ne nous attarderons pas trop sur ce problème, car c'est le cas d'une minorité de tableaux dans le livre. Et quand bien même certains tableaux auraient été découverts par cette méthode, ils ne présentent pas de résultats suffisamment impressionnants pour donner lieu à une étude approfondie.
Des résultats exactement conformes aux attentes
Il est curieux de constater que les résultats dans les tableaux proposés concordent exactement avec les calculs qu'on pourrait établir. Un fait flagrant est qu'on ne trouve pas de mots longs qui auraient été une preuve convaincante.
Si l'on observe les choses de près, on peut faire beaucoup d'autres constatations intéressantes :
- Une première remarque qui a toute son importance : si l'on recherche 50 mots ayant chacun 1 chance sur 50 d'apparaître, l'espérance de trouver un de ces mots s'élève à 1, c'est-à-dire qu'on a de bonnes chances d'en voir apparaître un. Un tableau ayant une espérance de 1 chance sur 50 n'a donc rien d'impressionnant. Le principe qu'il faut retenir de cet exemple est que, pour obtenir des résultats ayant une espérance relativement faible, il suffit de faire beaucoup d'essais. Une espérance assez faible n'a donc rien de surprenant. Un groupe de mots ayant une espérance de 1 sur 1000 n'est pas non plus très impressionnant, car quelques centaines d'essais sont bien vite effectués. Pour avoir des résultats vraiment surprenants, il faudrait dépasser les limites des combinaisons envisageables dans un temps raisonnable. Certains groupes de mots ont une espérance pouvant atteindre des chiffres très faibles comme 1 chance sur 1 million ; dans ce cas il n'est plus possible de dire qu'il suffit de quelques essais pour les trouver, mais il y a d'autres explications tout à fait naturelles. Et nous les avons déjà exposées (par exemple les tableaux voient leur espérance décroître très rapidement avec le nombre de mots contenu dans le tableau). Nous constatons que l'ensemble des tableaux se conforme à des résultats prévisibles : soit par des résultats relativement faibles (entre 1 chance sur 10 et 1 chance sur 1000 environ), il sont alors le fruit d'une insistance dans la recherche ; ou bien alors par des résultats plus faibles encore qui sont issus d'autres moyens de recherche.
- Une autre constatation montre que l'ensemble des résultats est prévisible : on remarque que les mots difficiles à trouver, les mots dont l'espérance mathématique est faible, n'apparaissent qu'une seule fois dans toute la Bible. On peut prendre l'exemple du groupe de mots 'Holocauste Atomique' dont l'espérance est de 1 sur 88. Ce groupe de mots est cité dans de nombreux tableaux du livre de Drosnin. Trouver des mots ayant une espérance si faible semble difficile ; mais en fait il suffit, comme nous l'avons expliqué, d'essayer un certain nombre de mots présentant la même idée. Avec une espérance de 1 sur 88, il a certainement fallu beaucoup de recherches pour trouver ce mot ; il est donc peu probable de le trouver une deuxième fois dans le texte biblique. C'est une déduction claire tirée de la valeur calculée.
Lorsqu'on observe tous les tableaux où ce mot apparaît, on constate que c'est bien toujours le même mot qui est cité. Ce groupe de mots n'a bien été trouvé qu'une seule fois, comme le calcul le laissait imaginer. En effet, lorsqu'on cherche à produire des tableaux, il est intéressant de trouver un mot d'une espérance faible et qui est plus riche de sens. Lorsqu'on a trouvé un mot difficile et qu'on cherche d'autres idées intéressantes à proximité, l'espérance des tableaux produits sera forcément assez faible. C'est ainsi que Drosnin a produit beaucoup de tableaux impressionnant du point de vue numérique comportant le groupe de mots 'Holocauste Atomique'. On peut constater que tous les tableaux qui présentent ce groupe de mots utilisent en fait exactement les mêmes lettres de la Torah. Voilà une constatation que les calculs permettent de prévoir.
- A l'inverse, lorsque des mots ont une espérance élevée, d'après le même raisonnement, on peut prévoir qu'il est possible de les trouver plusieurs fois dans la Torah. Or si l'on observe les différents tableaux du livre "La Bible : le Code Secret", on constate que les mots ayant une espérance élevée apparaissent bien sous des occurrences différentes du mot (c'est-à-dire à des lieux différents à l'intérieur de la Torah), comme le prévoient les calculs. C'est une remarque supplémentaire indiquant la conformité des découvertes par rapport aux calculs.
- Les ordinateurs cherchent de plus en plus vite, c'est pourquoi nous ne nous attarderons pas trop sur la vitesse de calcul qui est un frein à la découverte de tableaux impressionnants. Sans compter ce frein, il y a tout de même une limite à ce qu'on peut espérer trouver dans un texte d'une taille donnée. Si l'on prend la Torah par exemple, le nombre de positions possibles maximales pour un mot est de quelques dizaines de milliards (un peu plus de 90 000 000 000). Si l'on pouvait alors trouver des groupes de mots d'un seul tenant qui ont une espérance nettement inférieure à cette valeur (quelques centaines de milliards au moins, ce qui correspond à une phrase d'une quinzaine de lettres), alors on commencerait à atteindre la limite de ce qu'on peut espérer trouver dans le texte. Comme nous venons de l'exprimer, cette limite se calcule très facilement. Or si l'on regarde les espérances de tous les mots trouvés, on s'aperçoit que les valeurs sont tout à fait conformes aux attentes mathématiques et n'atteignent jamais de tels résultats.
Nous pouvons prononcer une conclusion globale : l'ensemble de tous les tableaux trouvés est tout à fait conforme à ce qu'on peut découvrir par une recherche soutenue ; on aurait même pu espérer des résultats encore plus élevés. Nous pourrions nous étendre plus longuement sur ces constatations qui montrent que les exemples suivent parfaitement les prévisions mathématiques, mais je pense que nous en avons suffisamment vu. N'est-ce pas la parfaite démonstration que l'ensemble des tableaux est tout à fait le fruit naturel du hasard ?
Des idées très malléables
Voilà une autre constatation qui a aussi son importance :
Si l'on observe bien le livre "La Bible : le Code Secret", on peut s'apercevoir que c'est bien souvent le contexte établi par l'auteur, avant ou après les tableaux, qui indique quel en est leur sens précis. Cela signifie que beaucoup de prophéties n'auraient aucune signification, ou alors un tout autre sens, si elles étaient présentées dans un autre contexte.
On peut citer pour exemple le tableau de la page 171 qui parle de 'la prochaine guerre'. Ce tableau est très révélateur d'une manipulation produite par le contexte. C'est avant de présenter le tableau que l'auteur a fixé un contexte très fort ; celui-ci induit très précisément le sens de la compréhension du tableau.
Si tous ces tableaux étaient réellement des prophéties, ils devraient pouvoir être compris clairement par tous ceux qui les observent. Ils ne devraient pas avoir besoin d'un contexte forgé par celui qui les présente, et encore moins d'un contexte qui n'a aucune trace dans le tableau.
Il serait nécessaire, pour admettre la validité du Code Secret, que les prophéties puissent être universellement comprises, sans contexte extérieur, sans le besoin d'un maître dont la révélation est nécessaire pour apporter le sens précis. Auquel cas, le procédé se confondrait complètement à une pratique de divination.
Il faut effectivement constater que cette malléabilité du contexte est utilisée pour de nombreuses prophéties présentées dans le livre. Cela est encore un argument convaincant sur l'invalidité du Code Secret pour qui veut bien l'entendre : soit les tableaux parlent par eux-mêmes avec une signification très précise, soit il y a vraiment lieu de les remettre en cause. Si l'on dresse le constat des tableaux présentés dans le livre, on s'aperçoit que beaucoup d'entre eux ont un contexte donné par l'actualité récente ; ils ne sont valables que pour nous, occidentaux de la fin du XXème siècle. Nous pouvons même aller plus loin : comme le sens des tableaux est fixé par l'auteur lui-même, ce sens n'est recevable que par ceux qui ont lu le livre de Drosnin...
Analyse de quelques tableaux
La partie qui suit est une étude de quelques tableaux du livre "La Bible : le Code Secret". Ces commentaires donnent une idée de ce qu'on trouve réellement à l'intérieur des tableau pésentés dans "La Bible : le Code Secret".
Les lecteurs qui voudront aller un peu plus loin pourront aussi s'intéresser aux autres tableaux qui se trouve en annexe 1 de ce livre.
Pour ce chapitre il peut être utile, mais non indispensable, d'avoir sous la main le livre "La Bible : le Code Secret" afin d'avoir une idée plus précise des tableaux qui sont étudiés. Nous allons commenter certains tableaux afin de déterminer quelles en sont les espérances précises
J'insiste encore une fois dans ce préambule, afin de ne pas le répéter sans cesse par la suite, sur le fait que dans les commentaires des tableaux tous les chiffres avancés sont basés sur le modèle que nous avons élaboré dans les chapitres précédents. Avec un autre modèle, on trouverait certainement d'autres valeurs (certainement comparables), c'est pourquoi le choix du modèle est très important et nous pensons avoir choisi un modèle objectif.
Encore une remarque importante afin de ne pas se méprendre sur les résultats. En les lisant, il faudra toujours penser comme suit : "l'espérance est de 20", signifie très exactement "au sens défini par le modèle, on risque d'obtenir environ 20 fois en moyenne le résultat du livre ou un résultat comparable sur l'ensemble des textes hasardeux de même constitution".
Avant de lire les résultats, ayons aussi le fait suivant bien à l'esprit : lorsque nous avons construit le modèle, il est apparu clairement que les chiffres que nous établissions avaient de bonnes chances d'être sous-évalués. Ainsi devant chaque résultat, nous pourrons toujours nous dire que des résultats plus précis seraient sans doute encore plus probables.
L'espérance qui résume chaque tableau peut être lue en-dessous de chaque titre.
Tableaux de la page de couverture du livre de Drosnin
(Que l'on peut retrouver avec d'autres précisions aussi pages 19, 20,31,32et 82)
L'espérance de ce tableau est de 1.1 (mais 0.1 pour le premier mot)
Ce tableau rassemble les mots suivants :
- Isaac Rabin
- Assassin qui assassinera
- Amir
- nom de l'assassin
- Netanyahou
- Tout son peuple à la guerre
Ce tableau est probablement l'un des plus surprenants du livre, c'est sans doute pourquoi il a été choisi par Drosnin comme couverture de son ouvrage. Il n'est pas le plus impressionnant quant aux valeurs mathématiques obtenues, mais quant au contenu qu'il possède. En effet, il correspond à une prophétie accomplie un an après son annonce.
On trouve sur ce tableau le nom 'Isaac Rabin' qui croise la phrase 'assassin qui assassinera', et d'autres phrases ne sont pas très éloignées.
Il est évident que le fait d'avoir prophétisé l'assassinat avant son accomplissement donne énormément de poids à la validité du Code Secret dans la Bible. Mais en observant de près le contexte de cette prédiction, on peut y relever de nombreux détails très intéressants :
- Premièrement, le code utilisé est un code 4772 (c'est d'ailleurs le seul code qui est cité dans le livre, page 31). C'est un code plutôt grand. Ainsi, le mot 'Isaac Rabin' s'étend sur 33 405 lettres, c'est-à-dire sur plus d'un dixième de toute la Torah. Pour que cette prophétie ait été annoncée par l'écrivain de la Bible il faudrait, d'après le principe que nous avons signalé en première partie , qu'il n'y ait eu aucune erreur de copistes sur toute cette partie de la Bible, ce qui est plus qu'improbable. Cela remet déjà bien en cause la prophétie, mais on pourrait supposer que les copistes n'aient fait aucune erreur...
- Voyons ensuite, l'espérance de cette apparition. Dans toute la Torah le nom 'Isaac Rabin' possède une espérance de 0.099, c'est-à-dire qu'il a en moyenne 1 chance sur 10 d'apparaître dans n'importe quel texte de la même taille. Cette probabilité ou espérance s'adresse à cette forme particulière du mot, mais il est possible d'imaginer beaucoup d'autres formes pour faire apparaître le même mot : par exemple 'Rabin Isaac' ou en lisant à l'envers le nom, le prénom : 'nibaR caasI' , ou bien encore en prenant les initiales du prénom plutôt que le prénom entier, etc... De cette façon, l'espérance de voir Isaac Rabin apparaître sous une forme ou une autre peut être très élevée. On peut ainsi être sûr de faire apparaître le nom de Rabin de très nombreuses fois dans la Torah.
- Il reste néanmoins que la forme qui est apparue est la plus belle de toutes. En effet les mots sont complets, ils sont lus à l'endroit et enfin ils sont dans l'ordre usuel de lecture pour nous occidentaux : prénom-nom. Cette forme possède une espérance mathématique de 1 sur 10. De plus elle croise la phrase 'assassin qui assassinera', ce qui n'est pas banal. Pour ce qui est de ce croisement nous avons déjà expliqué qu'il est impossible de le quantifier car c'est en fait une phrase du texte biblique proprement dit. Les connaisseurs de la Bible pourront se reporter à Deutéronome 4:42, c'est là qu'on la trouve.
- Il faut dire que les mots ayant trait à la mort dans le Pentateuque sont très nombreux. Nous allons le constater par un échantillon plus loin. Faire apparaître des mots faisant penser à la mort dans un tableau qui contient Isaac Rabin une fois que celui-ci est trouvé, ne ressort pas du tout de l'exploit. Il est vrai que le mot 'assassin' n'est pas omniprésent dans la Bible, donc le fait de le trouver croisant Isaac Rabin est une coïncidence plutôt remarquable, mais malheureusement celle-ci n'est pas mesurable ; ou plutôt aucun modèle ne peut mesurer l'espérance mathématique d'un fait unique, qui ne correspond pas à une répétition, comme nous l'avons déjà expliqué dans un précédent chapitre.
- Mais il faut, par ailleurs, considérer que si l'on cherche, on trouve. En effet, en cherchant bien, on trouve des choses remarquables. Et ce sont évidemment celles-ci qui sont publiées. Il faut bien comprendre que les mots 'Isaac Rabin' croisent un texte qui n'est pas fait de lettres au hasard, ce sont des mots réfléchis qui ont un sens voulu par l'auteur de la Torah. Faire apparaître des coïncidences comme celle-ci me paraît être le genre de découverte qu'on fait si l'on cherche suffisamment. En se souvenant que 'Isaac Rabin' est un ensemble de lettres qu'on risque de trouver plusieurs fois (si on accepte de le trouver à l'envers ou à l'endroit, le nom uniquement ou bien avec l'initial du prénom,...), il est plutôt facile de faire apparaître un mot parlant de mort à proximité. L'impression de ce tableau est essentiellement due au phénomène d'antériorité : lorsqu'une forme d'ordre est trouvée dans le hasard, elle semble toujours impressionnante mais, en fait, il suffit de chercher assez longtemps pour trouver quelque chose d'intéressant.
- Le point le plus impressionnant
qu'il reste à relever est donc celui de la prophétie.
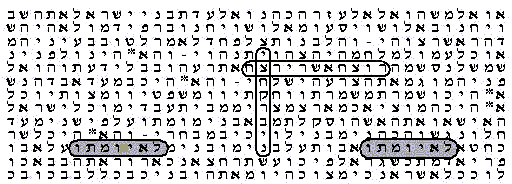
Mais dans cet ordre d'idée, on peut révéler un fait portant atteinte à la beauté prophétique de ce magnifique tableau. En effet, dans le même tableau, aux côtés des deux groupes de mots si impressionnants, figurent aussi en clair les mots suivants : 'Il ne mourra pas'. Cette phrase figure même deux fois très près des autres mots, comme vous pouvez le constater dans le tableau ci-dessous. Ce sont les deux groupes de mots situés en bas du tableau sur un fond grisé. La symétrie de l'apparition de ces deux phrases produit un effet d'impression supplémentaire : si le Code Secret est inspiré, il est clair que ces deux groupes de mots ont aussi leur place dans le tableau. - Si l'on interprète les mots prophétiques de ce tableau selon le principe de Drosnin, la prophétie serait alors : 'Isaac Rabin connaîtra une tentative d'assassinat, mais il ne mourra pas'. Comme la dernière idée est répétée deux fois, on peut insister fortement sur le fait qu'il ne mourra pas. Or la réalité a montré la tragique mort de Rabin...
- Il reste à expliquer comment Drosnin, un an avant l'événement, pouvait être assez sûr de lui pour annoncer prophétiquement aux autorités concernées qu'Isaac Rabin allait être assassiné. Je propose une explication possible ; elle est discutable, mais vaut la peine d'être entendue : Drosnin a tout simplement pris le risque d'annoncer prophétiquement un certain nombre d'événements. L'assassinat de Rabin s'est réalisé alors que d'autres événements n'ont pas confirmé ses prédictions. C'est d'ailleurs ce qu'il rapporte dans son livre : il cite plusieurs cas de prophéties non réalisées. Par exemple il avait prophétisé que tout le peuple hébreu irait à la guerre à la suite de la mort de Rabin, mais ceci n'a pas eu lieu. Mais Drosnin se rattrape, il a découvert, après coup, que les prophéties inaccomplies seraient retardées (p.174 de "La Bible : le Code Secret"). En fait, le calcul par les mathématiques nous permet de voir que le mot 'retardé' peut-être trouvé partout très facilement. Est-ce que l'auteur en trouvant ce tableau sur Rabin a réalisé que finalement il ne risquait rien à prophétiser l'assassinat de Rabin, car il avait pris ses précautions dans le texte au cas où l'assassinat échouerait ?
- De plus, Isaac Rabin menait une politique très dépréciée des groupes juifs intégristes. Il avait à dos de nombreuses personnes. Dans un tel climat, et en particulier dans la poudrière régnant autour de l'histoire moderne d'Israël, il n'était pas difficile d'imaginer un attentat contre Rabin. Dès lors, en recherchant 'Rabin' dans la Bible, Drosnin était sûr de trouver sous une forme plus ou moins impressionnante une prédiction de sa mort. Plus on cherche, plus on a de chances de trouver une forme intéressante ; c'est une corrélation mathématique indiscutable. Dans le cas où un attentat contre Rabin se produirait et échouerait, il serait toujours possible de dire que la Bible affirmait cela d'avance. Cette manière de procéder a été utilisée pour Netanyahou: c'est après coup que le mot 'retardé' a été trouvé dans le texte. Dans le cas où l'attentat contre Rabin aurait eu lieu sans échec, la phrase mentionnant qu'il ne mourrait pas serait passée sous silence. C'est probablement ce qui s'est produit. Il est peu probable que les inscriptions 'il ne mourra pas' soient restées inaperçues de Drosnin, car elles sont vraiment claires dans le texte, pour qui connaît l'hébreu.
- Comme nous l'avons dit, celui qui cherche trouve. Il ressort de tous ces commentaires que même si cette prophétie s'est réalisée, elle n'est peut-être pas si extraordinaire que cela. Elle n'est que le résultat d'une recherche approfondie sur un ordinateur, alliée avec un peu d'audace (celle d'annoncer la prophétie à l'avance) et de prudence (celle de pouvoir prédire le contraire le cas échéant).
Voyons maintenant de plus près les autres mots qui ont été trouvés près de ce même tableau et qui augmentent encore la précision de la prophétie. Il a été trouvé les mots 'nom de l'assassin' et 'Amir'.
Pour ce qui est du groupe de mots 'nom de l'assassin', celui-ci est en clair dans le texte. Il n'est donc pas mesurable, mais la Bible parle suffisamment d'assassins pour espérer faire apparaître cette idée. Une fois qu'on a trouvé le groupe de mots 'le nom de l'assassin' en clair, il est facilement possible de trouver n'importe quel mot de quatre lettres dans le même tableau et donc en particulier le mot 'Amir'.
En effet, la proximité du mot 'Amir' par rapport à 'Isaac Rabin' telle qu'elle a été trouvée dans le tableau p20, possède une espérance mathématique de 11. Cela signifie qu'à une telle distance, on pouvait espérer trouver ce mot plus de 11 fois, tout à fait naturellement. Ainsi, il est même fort probable qu'on puisse faire apparaître le mot 'Amir' à d'autres positions dans le même tableau. Celui-ci a certainement été choisi, car il se présente horizontalement, ce qui est une particularité esthétique supplémentaire. Jusqu'ici, il n'y a aucune surprise mathématique.
Il reste à voir les mots 'Netanyahou' et 'tout son peuple à la guerre' qui apparaissent à la page 82 du livre. Ce sont à nouveau des mots en clair, il est donc difficile d'en donner une estimation mathématique sensée. Mais il est tout de même possible de faire quelques remarques :
Pour ce qui est de 'Netanyahou' c'est un mot qui revient plus de 16 fois en clair dans la Torah. Il signifie tout simplement "Dieu donne". Il est donc facilement possible de le faire apparaître dans un tableau en utilisant les méthodes qui ont été expliquées. On voit de plus qu'il a fallu sauter trois lignes pour que celui-ci apparaisse. Ceci montre que le mot n'était pas directement présent dans le tableau d'origine.
Pour ce qui est de 'tout son peuple à la guerre', c'est une expression qui est loin d'être singulière pour la Torah. Il ne devait pas être très difficile de la faire apparaître dans le tableau. Il est par contre un peu plus remarquable de la trouver en clair précisément là où figure le mot 'Amir'. Mais de là à affirmer que c'est un prodige, ce ne serait pas juste. Cela peut tout simplement faire partie des choses qu'on trouve facilement quand on cherche longtemps. Cela ne veut pas dire qu'on trouve tout ce qu'on veut, mais que si l'on cherche, on trouve toujours des choses intéressantes.
Nous allons montrer comme il est aisé de faire apparaître des mots ou des phrases en clair qui ont un sens intéressant. Afin de pouvoir suivre ce travail, nous allons utiliser la traduction française du tableau sur 'Isaac Rabin'. Nous avons rassemblé ci-dessous le texte traduit des phrases qui entourent chaque lettre du mot 'Isaac Rabin' en clair. Ce sont des portions du texte biblique prises toutes les 4772 lettres puisqu'elles contiennent les lettres du mot 'Isaac Rabin'. Nous avons choisi de travailler sur un tableau assez large : sur chaque ligne de ce tableau on peut voir la phrase qui contient une lettre du mot 'Isaac Rabin', la phrase d'avant et celle d'après. Ce texte, que vous verrez ci-après, n'est pas présenté sous forme de tableau, mais d'un texte continu.
En cherchant un peu, il est fort possible de construire beaucoup d'associations d'idées des plus saugrenues. Nous donnons ci-dessous un exemple presque ridicule qu'il ne faudrait pas prendre au sérieux, surtout lorsqu'on pense au contexte si tragique des événements auxquels il fait référence. Mais nous présentons cet exemple pour montrer qu'il est bien facile de construire des histoires montées de toutes pièces dans des tableaux. Il suffit pour cela de mettre en valeur certains mots ou certaines phrases en oubliant les autres.
Nous avons construit toute une histoire en ne retenant que certains passages. Si on lit uniquement les mots qui sont mis en gras dans le texte ci-dessous, on peut y trouver l'histoire suivante : "Isaac Rabin a été blessé par un homme qui ne l'a pas fait exprès. Cet homme n'avait jamais cultivé aucune rancune contre Rabin. Heureusement, Rabin ne mourra pas de ses blessures ; il sera sauvé comme par miracle. Il ne faut surtout pas qu'il se fasse de soucis, car la prophétie dit bien qu'il ne mourra pas.
Certaines personnes feront semblant d'étudier l'histoire de cette tentative ratée afin de voir ce qui s'est réellement passé pour que cela ne se reproduise plus. Ils interrogeront l'assassin involontaire dans le bureau de Rabin. En fait, ces gens seront secrètement soudoyés pour le service de Rabin afin de le venger. Ils mettront à mort le pauvre homme. Cela sera connu et entraînera beaucoup de contestations dans le pays, mais ces hommes sauront répondre à ces contestations et ils redresseront la situation."
Voici les phrases du tableau, qui donne lieu à cette découverte :
L'Eternel me dit : Vois, je te livre dès maintenant Sihon et son pays. Sihon sortit à notre rencontre, avec tout son peuple, pour nous combattre à Jahats. L'Eternel, notre Dieu, nous le livra, et nous le
battîmes, lui et ses fils, et tout son peuple. Alors Moïse choisit trois villes de l'autre côté du Jourdain, à l'orient, afin qu'elles servissent de refuge au meurtrier qui aurait involontairement tué son prochain, sans avoir été auparavant son ennemi, et afin qu'il pût sauver sa vie en s'enfuyant dans l'une de ces villes. Les grandes épreuves que tes yeux ont vues, les miracles et les prodiges, la main forte et le bras étendu, quand L'Eternel, ton Dieu, t'a fait sortir : ainsi fera L'Eternel, ton Dieu, à tous les peuples que tu redoutes. L'Eternel, ton Dieu, enverra même les frelons contre eux, jusqu'à la destruction de ceux qui échapperont et qui se cacheront devant toi. Ne sois point effrayé à cause d'eux ; car L'Eternel, ton Dieu, est au milieu de toi, le Dieu grand et terrible. Tes pères descendirent en Égypte au nombre de soixante-dix personnes ; et maintenant L'Eternel, ton Dieu, a fait de toi une multitude pareille aux étoiles des cieux. Tu aimeras L'Eternel, ton Dieu, et tu observeras toujours ses préceptes, ses lois, ses ordonnances et ses commandements. Reconnaissez aujourd'hui ce que n'ont pu connaître et voir vos enfants les châtiments de L'Eternel, votre Dieu, sa grandeur, sa main forte et son bras étendu, ses signes et ses actes qu'il a accomplis au milieu de l'Égypte contre Pharaon, roi d'Égypte, et contre tout son pays. Mais tu le feras mourir; ta main se lèvera la première sur lui pour le mettre à mort, et la main de tout le peuple ensuite; tu le lapideras, et il mourra, parce qu'il a cherché à te détourner de L'Eternel, ton Dieu, qui t'a fait sortir du pays d'Égypte, de la maison de servitude. Il en sera ainsi, afin que tout Israël entende et craigne, et qu'on ne commette plus un acte aussi criminel au milieu de toi. Dès que tu en auras connaissance, dès que tu l'auras appris, tu feras avec soin des recherches. La chose est-elle vraie, le fait est-il établi, cette abomination a-t-elle été commise en Israël, alors tu feras venir à tes portes l'homme ou la femme qui sera coupable de cette mauvaise action, et tu lapideras ou puniras de mort cet homme ou cette femme. Celui qui mérite la mort sera exécuté sur la déposition de deux ou de trois témoins; il ne sera pas mis à mort sur la déposition d'un seul témoin. Ils feront descendre cette génisse vers un torrent qui jamais ne tarisse et où il n'y ait ni culture ni semence; et là, ils briseront la nuque à la génisse, dans le torrent. Alors s'approcheront les sacrificateurs, fils de Lévi; car L'Eternel, ton Dieu, les a choisis pour qu'ils le servent et qu'ils bénissent au nom de L'Eternel, et ce sont eux qui doivent prononcer sur toute contestation et sur toute blessure. Tous les anciens de cette ville la plus rapprochée du cadavre laveront leurs mains sur la génisse à laquelle on a brisé la nuque dans le torrent.
Comme nous l'avons expliqué, ces phrases sont tirées de plusieurs passages espacés dans la Bible. C'est l'occasion de voir qu'il est très souvent parlé de mourir, de meurtres, d'assassins... La découverte du mot Rabin au milieu d'un tel passage n'est donc pas si extraordinaire qu'elle ne paraît.
Il serait possible de construire une toute autre histoire qui se tienne un peu mieux que la nôtre. En conclusion, on voit qu'il est facile de fabriquer des prophéties à partir d'un texte quelconque en faisant ressortir quelques mots.
On pourrait d'ailleurs concevoir un jeu de société sur ce principe : à partir d'un texte donné, essayer de construire une histoire qui tient debout en tirant des mots du texte. Le jeu n'est pas très difficile et il est assez intéressant, mais il faudra faire attention à ne pas le prendre trop au sérieux. On voit comme il est facile de faire dire beaucoup de choses à n'importe quel texte, à condition d'y prendre un peu de soin et d'infléchir les contextes.
Espérance : 15 (avec 0.42 pour le premier mot)
- Feu le 3 shevat (ce qui correspond au 18 janvier) - Ennemi
- Sadam - Hussein
- Missile - Guerre
Le premier mot 'le 3 shevat, feu !' tel qu'il apparaît dans le texte, présente une espérance de 0.42 c'est-à-dire un peu moins de 1 chance sur 2; très exactement 1 chance sur 2.36 en moyenne. De plus cette espérance est considérablement augmentée, si l'on l'on accepte d'autres ordres pour les mots de la phrase. Par exemple en acceptant la possibilité de trouver 'le 3 shevat, feu !' indifféremment de 'feu, le 3 shevat !' - ce qui signifie la même chose - l'espérance est pratiquement de 1. Ainsi, on a toutes les chances de trouver cette association de deux mots dans le texte.
Ajouter le mot 'Hussein' tel qu'il se trouve dans le passage présente une espérance mathématique de 68 ; cela signifie qu'à une telle distance, on est susceptible de pouvoir trouver 68 fois le mot 'Hussein'.... En cherchant bien, il est donc peut-être possible de trouver ce mot 'Hussein' encore mieux placé.
Trouver le mot 'ennemi', à proximité des deux derniers mots, Présente une espérance de 0.031, soit environ 1 chance sur 33 en moyenne. Cela vient du fait que le mot est collé très près du mot 'Hussein'. C'est sans doute pour cela que ces deux mots ont été choisis ainsi ; mais le tableau n'a rien d'extraordinaire pour autant. Il faut se rappeler qu'il y a une espérance de 68 pour 'Hussein'. Ainsi, l'espérance des trois mots est de 0.89, soit 89% de chance de découverte, en moyenne : C'est une valeur assez grande. Ce tableau ne représente donc pas de difficulté majeure à être trouvé dans le texte.
Le mot 'missile' ne présente aucune difficulté à être trouver lui non plus. L'espérance mathématique de le trouver rapproché des mots précédents est de plus de 17.
Il reste les mots 'Sadam' et 'Guerre' qu'on peut lire directement dans le texte sans sauter de lettres.
En observant ce tableau, on peut se poser des questions. Par exemple : pourquoi n'a-t-on pas trouvé le mot 'Sadam Hussein' d'un seul tenant ? En effet, il est peu logique de trouver ces deux mots séparés. Ne semble-t-il pas curieux de trouver le mot 'Sadam' complètement à l'écart du mot 'Hussein', et avec un autre code en plus ? On comprend peut-être plus facilement ce tableau lorsqu'on pense que 'Sadam' est un mot hébreu de trois lettres, il est donc très facile à produire...
Par ailleurs le mot 'guerre' est une idée assez courante de la Torah. Ecrit de la sorte, il se trouve 20 fois. C'est vrai que c'est trop peu pour espérer le trouver dans tous les tableaux ; mais vu le contexte de ce tableau, trouver le mot 'guerre' à cet endroit là semble ressortir tout naturellement du principe de l'antériorité. On aurait facilement pu trouver des mots comme 'des morts', 'la peur' ou je ne sais quels autres mots qui s'appliqueraient bien à relever ce contexte.
Ce tableau a une espérance supérieure à 15, le plus difficile à découvrir étant le premier groupe de mot (avec presque une chance sur deux en moyenne malgré tout).
Espérance : 0.12 (soit un peu plus de 1 chance sur 9)
Ce tableau présente les mots suivants :
- Effondrement économique
- Dépression
- Actions
- 1929
Le mot 'dépression' est en toute lettre, nous ne nous y attarderons pas.
Voyons ce qu'il en est pour les autres mots :
Le mot 'Effondrement économique' qui est le mot principal possède une espérance de 1.7. En pensant en plus qu'on peut facilement trouver la même idée sous d'autres formes, ce mot n'est pas difficile à faire apparaître.
Pour ce qui est de faire apparaître le mot 'action' à la proximité qu'on peut constater du mot principal, l'espérance est de 0.17, ce qui donne comme espérance pour les deux mots 0.3. C'est un peu moins de 1 chance sur 3 en moyenne, ce qui signifie qu'après environ trois essais de même difficulté, on peut raisonnablement espérer faire apparaître un tel tableau. Ceci n'a rien de spectaculaire...
Pour le mot '1929', l'espérance de le trouver à une telle proximité des deux premiers mots que nous venons d'étudier est de 0.39 ce qui est ne semble pas impossible. Sur trois essais portant sur une difficulté semblable, il apparaît en moyenne 1 tableau similaire, voire 2.
Le calcul mathématique de l'espérance nous fourni le résultat suivant : pour faire apparaître un tableau semblable à celui de la page 37 avec un ordinateur assez puissant, on peut raisonnablement supposer qu'avec neuf essais de même difficulté, on a de bonnes chances d'en voir apparaître un. Si le mot 'action' était un tout petit peu plus éloigné du mot principal, l'espérance grandirait d'autant plus. Si bien qu'il ne faudrait pas s'éloigner bien loin pour obtenir une espérance supérieure à 1. Cette remarque pour dire que le tableau n'est pas exceptionnel.
Nous avons d'ailleurs donné, dans la seconde partie, un exemple similaire de tableau en français cherché à partir d'un texte fait de lettres tirées au hasard.
Deuxième tableau de la page 53
Espérance : 35
Ce tableau présente les mots suivants :
- Newton
- Gravité
L'espérance de trouver le mot 'Newton' est de 246. Cela signifie qu'il est possible de le trouver 246 fois dans le texte, en théorie.
L'espérance de trouver le mot 'gravité' à cette proximité est de 0.14.
D'où l'espérance de trouver les deux mots ainsi rapprochés est de 35. On peut dire que cela est plutôt très facile.
Espérance : 0.000063 (soit 1 sur 16 000)
Ce tableau présente les mots suivants :
- Oklahoma
- Terrible mort effrayant
- Il y aura de la terre (en clair)
L'espérance de 'Oklahoma' est de 9.
L'espérance de trouver 'terrible mort effrayant' à cette proximité est de 0.000007.
Voilà qui est très faible on obtient une espérance totale pour les deux mots de 0.000063 à savoir 1 chance sur 16 000 en moyenne. Le résultat élevé de ce tableau provient de la proximité très étroite de deux mots assez longs. Ils sont, pour ainsi dire, collés l'un à l'autre. C'est pourquoi l'espérance obtenue est très faible, notre modèle a été ainsi conçu.
Voilà enfin un résultat qui ressemble à quelque chose d'important. Est-ce une preuve pour autant ? En fait, il y a plusieurs remarques à faire sur ce tableau :
- Cette valeur de 16 000 peut être divisée par le nombre de façons possibles dont on peut exprimer les mêmes idées de 'mort effrayante', avec sept lettres en hébreu ; Sans doute peut-on facilement le dire de 100 façons avec tous les dérivés : 'terrible mort', 'mort terrible', 'mort tragique', 'tragique mort', 'mort horrible', 'horrible mort', sans parler des mots plus éloignés tels que 'victimes', 'attentat'... La recherche peut être longue. Avec seulement 100 façons de le dire, l'espérance augmente à 1 sur 160, un chiffre qui n'est plus très élevé.
- Même en supposant que ce tableau ne peut se trouver que d'une seule façon avec une espérance de 1 sur 16 000, cela veut dire qu'on peut trouver ce genre de tableau 1 fois sur 16000 recherches du même type. Il est vrai que 16 000 recherches, c'est plutôt beaucoup. Mais avec un ordinateur, c'est très vite réalisé ; surtout lorsqu'on recherche, comme c'est le cas ici, des tableaux de plusieurs mots imbriqués. Les combinaisons ne s'ajoutent pas mais se multiplient pour augmenter les possibilités de découvertes. On atteint assez vite des résultats de 1 sur 16 000. Donc 1 sur 16 000 par lui-même n'est pas un résultat déterminant pour montrer qu'il est extraordinaire. De très nombreux essais conduisent obligatoirement à ce genre de découvertes, c'est une loi mathématique très facilement vérifiable.
- Cette prophétie biblique est censée parler de l'attentat contre un bâtiment fédéral à Oklahoma-City le 19 avril 1995. Or les seuls mots qu'on trouve sont 'Oklahoma' et 'terrible mort'. On ne trouve pas d'année, pas de contexte, pas de précision sur l'attentat, pas de mot 'camion bourré d'explosif', aucune précision ; si bien qu'en considérant les seuls mots découverts, on peut se poser des questions sur la prophétie : Il y aura des morts effrayantes à Oklahoma ! En effet, il risque fort d'y avoir des morts effrayantes dans n'importe quelle grande ville durant toute son histoire. Le sens de cette prophétie est vraiment très léger lorsqu'on le considère sans le contexte imposé par l'auteur.
- L'espérance de trouver le même tableau sans le mot 'effrayante', avec les seuls mots 'Oklahoma' et 'mort' disposés exactement de la même façon est de 13 ; ce qui est un résultat facile. C'est donc uniquement le mot 'effrayante' qui vient réduire l'espérance à 1 sur 16 000, mais qu'apporte réellement de plus ce mot à la prophétie ? Est-ce que la frayeur a vraiment été un élément très caractéristique de l'événement cité ? N'y a-t-il pas eu à Oklahoma des morts dont la frayeur a été bien plus grande encore ? Il est certain que si. Si c'est uniquement ce mot 'effrayant' qui est spectaculaire, peut-on dire qu'il est bien démonstratif d'une prophétie révélée ?
- Voyons le second groupe de mots. Comme nous l'avons déjà expliqué, il assez facile, dans le principe, de chercher des mots qui se suivent. Il suffit d'observer si une des occurrences du mot cherché (ici le mot 'mort') s'inscrit dans une phrase, si les lettres avant ou après forment un mot intéressant. Ici, c'est le cas du mot 'effrayant' qui s'ajoute au mot mort. Et celui-ci va forcément réduire l'espérance. En effet c'est un mot de 4 lettres en hébreu. On pourra consulter à ce titre les remarques faites sur le tableau avant et les remarques faites en préliminaire à cette IVème partie. Peut-être ce tableau n'est finalement que le hasard d'une recherche sur plusieurs mots, il serait donc moins impressionnant qu'il ne paraît.
En conclusion nous dirons que ce tableau est tout de même impressionnant. Mais que la valeur de son espérance est très faible comparée à ce qui serait nécessaire de trouver pour être démonstratif. En effet, avec la puissance de calcul des ordinateurs, 16 000 essais de recherches ne représentent vraiment pas grand chose. Il faudrait des espérances d'au moins 1 sur 1 000 000 000 000 000 pour être certain que ce n'est pas le fruit de la multitude des recherches d'un ordinateur. Il faudrait peut-être même un nombre peu plus grand lorsqu'on pense à la rapidité d'évolution des ordinateurs. Ce chiffre paraît immense et inaccessible et pourtant il n'est pas si éloigné qu'il ne paraît : il suffirait de trouver une phrase de 20 lettres d'un seul tenant pour atteindre un tel chiffre (20 lettres est une estimation moyenne, cela dépend des lettres dont elle serait composée). Trouver une phrase de 20 lettres ne semble pas extraordinaire, et pourtant cela serait une découverte commençant à être convaincante. Alors qu'en serait-il d'une phrase de 30 lettres ?... Or rien de tout cela. Les résultats que nous obtenons sont toujours très évidents, et de temps en temps un peu plus élevés, mais toujours facilement accessibles.
Nous avons vu que si un tableau obtient un résultat de 1 sur 6, il suffit de 6 essais différents, pour espérer trouver ce tableau. Pour être précis mathématiquement, cela signifie que six essais donne une espérance de 1. Cela signifie que le résultat apparaît en moyenne dans un livre sur 6 parmi de nombreux livres de même taille que la Torah. Comme la Torah est un livre aux lettres bien mélangées, l'espérance collera d'assez près aux constatations pratiques. C'est pourquoi cette façon de parler n'est pas complètement erronée, elle permet de se faire une idée.
Par ce raisonnement, avec tous les résultats que nous trouvons au travers de tous les tableaux du livre "la Bible : le Code Secret" (voir aussi l'annexe), il suffirait de 66 300 essais (ou 9300 sans compter les deux tableaux les plus forts) pour faire un travail semblable. Avec un ordinateur assez puissant et des listes de mots, ce chiffre est très vite atteint. Les résultats ne sont donc nullement probant. Un résultat demandant 66 300 essais n'a aucune valeur mathématique de mesure. C'est juste un ordre d'idée de la difficulté qui résume l'ensemble de résultats découverts. On s'aperçoit que c'est, malgré tout, une grosse somme de travail.
Au terme de cette étude de cas concrets, il apparaît très nettement que l'existence de ce code dans la Bible qui contiendrait l'avenir et le passé tout tracé n'est pas présente. Aucun résultat ne le montre. De plus comme nous l'avons expliqué, si le code existait vraiment, il aurait été facile de le repérer. Or personne n'en a trouvé aucune trace. Conclusion : je la laisse au lecteur... Ou plutôt non ! Je vais finir par des considérations bassement personnelles.
Il est bien dommage que mon nom soit : klopfenstein
En effet 12 lettres, dont plusieurs assez rares (orthographe hébraïque que j'ai choisie pour rendre le nom phonétiquement), donnent peu de chances à mon nom de figurer dans la Torah par la méthode du Code Secret, en vertu des calculs que nous avons faits. Pourtant, pour avoir contribué au dénouement du Code Secret, j'aurai peut-être modestement pu y figurer. Mais toutes les tentatives effectuées pour trouver mon nom furent infructueuses, ce n'est pas étonnant avec une chance sur 16 956 414. Oui, malheureusement pour moi je suis né avec un nom contenant trop de lettres ...
|
Du même auteur : | ||||
| Connexion privée | Contact | Proposer de l'aide | Signaler un problème | Site philosophique flexe |