|
Mise en perspective du Théorème de Gödel
|
|
|
|
A partir d'un regard philosophique sur la nature des mathématiques, le theoreme de Gödel (...)
|

Archivis
"Mais dans quel CD est-ce que ce trouve ce texte qui parle des haricots?"
"Dans quel répertoire est donc cet article ou ce film ?"
Soit vous êtes une mémoire prodige et une organisation minutieuse, soit un logiciel comme Archi peut vous être vite indispensable.
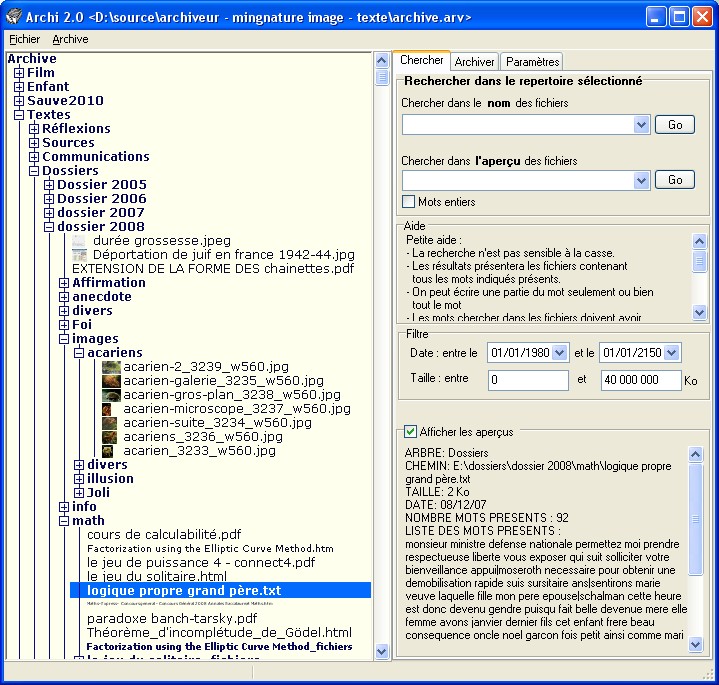
Ce logiciel sert à repertorier tous vos fichiers. Il "suffit" de scanner une fois tous vos CD, vos disque durs , il les retient en mémoire. Le plus impressionnant : Archi stock une miniature du contenu de vos fichiers, image ou texte.
Aussi il est donc possible de faire une recherche très rapide non seulement sur les titres, mais aussi sur le contenu de vos fichiers et cela avec une taille de stockage réduite au maximum.
Nom du logiciel : Archivis
Version : 2.0
Environnement : de Windows 95 à win10 (Sous Mac O.S., voir avec un émulateur windows)
Taille : 1 Mo
Langue : Français
Année de lancement : 2010-2025
Editions : Mike°Soft (C)
Licence : Usage gratuit
Logiciel ayant trait aux thèmes : Pratique - Utile - Utilitaire - Manipuler_fichiers - Media
Archivage:
On connecte un disque dur, on entre un titre et le repertoire voulu. Il scanne tout dans l'archive. De nombreuses options d'archivage : les extensions à éviter, les extensions auquelles il faut eventuellement se limiter. Les extensions dont le contenu doivent être analysé, ceux que l'on sait être compatible.
Puis une fois tous les disques scannés on dispose d'un apercu.
Créer autant d'archives différentes que vous le souhaitez (Archi manipule les extensions *.arv).
La dernière archive utilisée se relance avec le logiciel.
Apercu:
- Tous les fichiers se présentent sous forme d'arborescence de repertoires que l'on peut parcourir, déployer et refermer selon l'usage commun.
- Chaque nouvel archivage peut être placé n'importe où dans l'arbre.
- On dispose d'un apercu des mots présents dans les fichiers textes parmi une multitude d'extensions intégrées (TXT - LOG - CSV- PHP - H - PAS - DOC - DOCX -SXW - SXC - ODT - ODS - ODP- PPT - PPTX- -RTF - XLS - XLSX - XML- HTML - HTM ) et même DBX (fichier outlook) dont le logiciel va extraire les messages *.eml en retenant leur contenu.
- On dispose d'un apercu des fichiers images (jpeg,bmp, gif, png), en miniatures visibles dans l'arborescence et en miniatures grossies quand on clique sur l'image.
- Ces arbres sont manipulables : on peut les déplacer dans <l'arbre visible> de telle sorte qu'on peut aisement le repositionner comme on veut. On peut aussi supprimer, créer manuellement des branches pour réorganiser les archives de façon souple. On peut aussi renommer , déployer tout une branche, la réduire,...
- Après toutes manipulations sur l'arbre, on peut recalculer la taille des arbres.
Recherche:
On dispose bien évidemment, c'est le but, d'une recherche sur les contenus :
- Le resultats est fourni sous forme d'un tableau
- Rapide même sur des millions de fichiers scannés
- On peut chercher sur le noms des fichiers mais aussi dans les contenus scannés.
- En double-cliquant sur l'entête d'une colonne, le tri est effectué selon tous les critères disponibles. En recommançant, il est renversé.
- En cliquant sur une donnée, on dispose de l'apercu.
- En double-cliquant sur une donnée, cela lance le fichier sours l'environnement Windows lorsque le fichier est accessible. Ce qui permet de manipuler les recherches et de consulter directement.
- Ce sont tous les mots présents à l'interieur des fichiers qui sont scannés, ce qui permet d'effectuer une recherche à l'intérieur des fichiers, un fichier est sélectionné comme résultat s'il contient tous les mots indiqués.
Sauvegarde
Un système de sauvegarde des archives est activé par défaut. C'est un système logarithmique : il fait une copie à chaque fermeture et conserve de façon intelligente et automatique les copies les plus anciennes et les plus récentes en supprimant au fur et à mesure celles qui ne sont plus utiles. De sorte qu'on ait toujours l'histoire complète mais courte de toutes les sauvegardes (en une vigntaine de fichiers).
Les sauvegardes sont placées dans le répertoire Sauvgrd de l'installation du logiciel. Pour la récupérer renommer la en *.arv
Astuces
- on peut scanner tous les disques durs sans fabriquer d'apercus, et puis fabriquer un apercu sur des répertoires explicitement plus spécifiques.
-on peut sauvegarder systématiquement dans une archive unique pour avoir tout sous la main, puis fabriquer des archives plus petites en supprimant des parties (cela produit des archives plus rapides à charger pour des recherches fréquentes)
Limites
- les dates sont forcément situées entre 1980 et 2150 et les heures ne sont pas prises en comptes (pour réduire la place de stockage au minimum)
- Les tailles des fichiers sont arrondies à des valeurs logarithmiquement proches, ce qui modifie légérement les totaux et les tailles.
- Pour des questions d'efficacité de tri, la liste des recherches se limite aux 1000 premières données trouvées.
-Pour des questions de stockage et d'affichage sur d'éventuels fichiers 'hasardeux', le nombre de mots stocker dans un fichier est limité à 20 000. Ce qui est le cas de la plupart des livres dans toutes les langues. Cette limitation est donc peut rencontrée en pratique.
- Les images sont évidemment de piètre qualité car stockée en peu de place, mais assez souvent suffisante pour se rappeler de l'allure d'une image déjà vue.
- Les recherches sur le noms portent sur les chiffres et les lettres, mais les recherches dans les fichiers ne portent que sur les lettres.
Remarques techniques:
- Exemple de taille de stockage : 33 Mégaoctets pour stocker environ 300 000 fichiers dont beaucoup d'images et de textes permettant d'acceder à leur contenu. (sans compter le fichier des mots communs à tous les archivages qui prend aussi une trentaine de Mégaoctets)
- les dates sont renversées (aa-mm-jj) pour la lisibilité d'ordre lexicographique.
- les archives sont stockées dans deux fichiers : un fichier "liste de mots" unique pour toutes les archives et un fichier contenant les informations de chaque fichier dont des codes pointant vers ces mots.
- Pour la rapidité, un code est attribué à chaque mot et il arrive que plusieurs mots aient le même codes. Ces mots sont alors affichés ou recherchés ensemble, car Archi ne sait pas les distinguer (en général le contexte le permet facilement). À l'affichage les mots sont séparés par le symbole '|', un seul des mots affichés aura été trouvé dans le texte. Si un tel mot multiple (voir remarque technique) vous gêne et que le second mot n'a aucun intérêt vous pouvez toujours le supprimer en ouvrant le fichier list-mot.txt (avec un éditeur du type Notepad++) et supprimer le mot inutile qui ne sera pas ajouter jusqu'à ce qu'il soit rencontrer dans un nouvel archivage.

|
Analyse de Fourier
|
|
|
Logiciel d'analyse de Fourier d'une fonction périodique donnée (graphe,séries,h (...)
|

|
Adapter la taille à un rectangle
|

|
|
Coupe/Ajoute une image en son milieu pour atteindre une taille donnée
|

|
Du même auteur : | ||||
| Connexion privée | Contact | Proposer de l'aide | Signaler un problème | Site philosophique flexe |